DeepSeek V4: 1.6T Parameters, 1M Context, at 1/10th the Price

On April 24, 2026, Chinese AI lab DeepSeek released DeepSeek V4 — and it’s shaking up the entire LLM market. With two variants (V4-Pro and V4-Flash), a massive 1M token context window by default, and pricing that undercuts competitors by 10-100x, this is the biggest open-source model release of 2026.
The Two Models
| Model | Total Parameters | Active Parameters | Best For |
|---|---|---|---|
| DeepSeek-V4-Pro | 1.6 Trillion | 49 Billion | Complex reasoning, math, agentic coding |
| DeepSeek-V4-Flash | 284 Billion | 13 Billion | Speed, cost-efficiency, high-volume tasks |
Both use a Mixture-of-Experts (MoE) architecture, meaning only a fraction of parameters are activated per task — drastically reducing inference costs while maintaining frontier-level performance.
V4-Pro is currently the largest open-weight model available, surpassing Moonshot AI’s Kimi K2.6 (1.1T) and more than doubling DeepSeek’s own V3.2 (671B).
Benchmark Results
DeepSeek V4-Pro delivers impressive results across coding, reasoning, and knowledge benchmarks:
| Benchmark | V4-Pro Max | Notes |
|---|---|---|
| SWE-bench Pro | 55.4% | Real-world GitHub issue resolution |
| SWE-bench Verified | 80.6% | Verified code fix accuracy |
| Terminal-Bench 2.0 | 67.9% | Autonomous CLI tasks |
| LiveCodeBench | 93.5 | Competitive programming (SOTA) |
| GPQA Diamond | 90.1% | Graduate-level reasoning |
| BrowseComp | 83.4% | Web research |
| MCPAtlas Public | 73.6% | Tool use & function calling |
| Codeforces Rating | 3206 | Competitive programming (SOTA) |
| IMOAnswerBench | 89.8 | Math olympiad problems (SOTA) |
| MMLU-Pro | 87.5% | Matches GPT-5.4 |
The standout numbers are 93.5 on LiveCodeBench and 3206 Codeforces rating — making V4-Pro the best model for competitive programming and algorithmic challenges. It also leads all open models in agentic coding benchmarks.
Architecture Innovation
DeepSeek V4 introduces a novel attention mechanism combining:
- Token-wise compression — reduces redundant information
- DSA (DeepSeek Sparse Attention) — selective attention over long contexts
The result? V4-Pro’s hybrid CSA+HCA attention reduces the KV cache to just 10% of V3.2’s footprint at 1M context. This is a massive efficiency gain for long-document and large-codebase processing.
Pricing — The Real Game Changer
| Model | Input (/1M tokens) | Output (/1M tokens) |
|---|---|---|
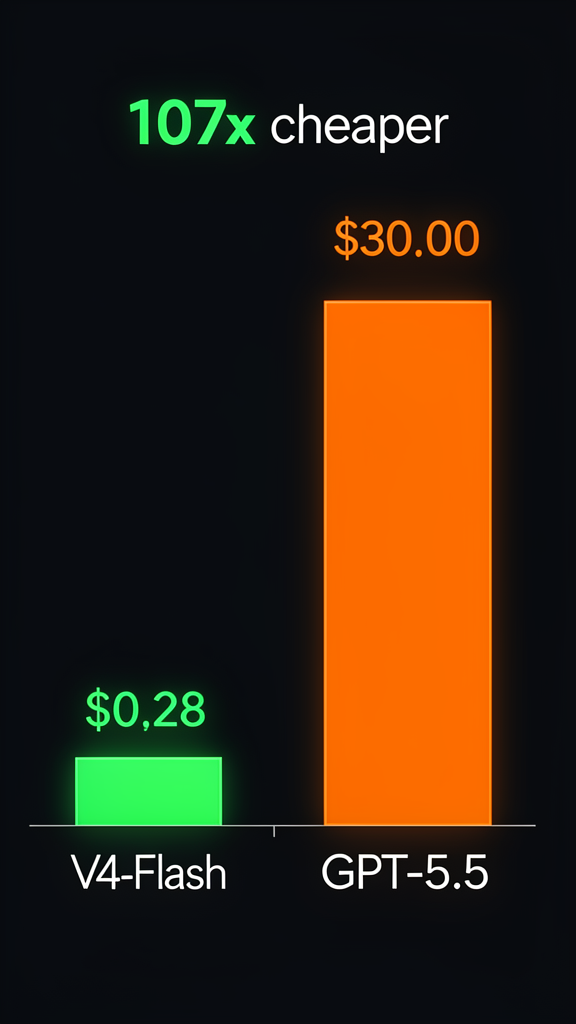
| V4-Flash | $0.14 | $0.28 |
| V4-Pro | $1.74 | $3.48 |
| Claude Opus 4.7 | $15.00 | $25.00 |
| GPT-5.5 | $5.00 | $30.00 |
Processing 10M output tokens costs:
- $34.80 with V4-Pro
- $250 with Claude Opus 4.7
- $300 with GPT-5.5
V4-Flash is 90-107x cheaper than premium models while still delivering competitive quality on many tasks.
1M Context — Default, No Surcharge
Unlike competitors that charge extra for extended context, DeepSeek V4 includes 1M token context by default across all services. No surcharge, no tier restrictions. This is huge for:
- Full codebase analysis
- Long document processing (legal contracts, research papers)
- Multi-file refactoring projects
- Comprehensive research synthesis
API & Integration
- Compatible with OpenAI ChatCompletions and Anthropic APIs
- Model IDs:
deepseek-v4-pro|deepseek-v4-flash - Dual modes: Thinking and Non-Thinking
- Works with Claude Code, OpenClaw, OpenCode, and other AI agents
Migration
Just update your model identifier — the base_url stays the same.
⚠️ Deprecation warning:
deepseek-chatanddeepseek-reasonerwill be retired after July 24, 2026. Legacy endpoints are already auto-routing to V4-Flash.
Open Source & MIT License
Both V4-Pro and V4-Flash weights are available under the MIT License on HuggingFace. This means you can:
- Self-host on your own infrastructure
- Fine-tune for your specific use case
- Keep data on-premise (critical for regulated industries)
- Avoid vendor lock-in
This is the most powerful open-source model ever released, and it’s freely available to anyone.
Weaknesses to Know
- Text-only — no image, audio, or video support
- World knowledge gap — trails GPT-5.4 and Gemini 3.1 Pro on factual recall (SimpleQA-Verified: 57.9 vs 75.6 for Gemini)
- Developmental lag — DeepSeek admits they trail frontier models by ~3-6 months on knowledge benchmarks
- Geopolitical risk — hosted API routes through Chinese infrastructure; self-hosting recommended for compliance-sensitive use cases
Should You Use It?
Absolutely, if you:
- Need cost-efficient high-volume inference (V4-Flash at $0.28/M output tokens)
- Run competitive programming or math-heavy workloads (V4-Pro SOTA)
- Want open-source, self-hostable models (MIT license)
- Process large codebases or documents (1M context, no surcharge)
- Build AI agents on a budget
Look elsewhere if you:
- Need multimodal capabilities (images, audio, video)
- Require the absolute best factual world knowledge
- Have strict data sovereignty requirements (self-host V4 to solve this)
Verdict
DeepSeek V4 is the most cost-effective frontier model on the market. V4-Pro leads competitive programming and math reasoning, while V4-Flash delivers 80%+ of the quality at less than 1% of the cost. Combined with the MIT license and 1M context by default, this release fundamentally changes the economics of AI development.
The 3-6 month knowledge gap is real, but for coding, math, and agentic tasks, V4 is already at the frontier. At 1/10th the price of Claude and GPT, that’s an incredible value proposition.
Are you switching to DeepSeek V4? Which variant are you testing first? Drop your thoughts in the comments!
Enjoying the content? Here are tools I personally use and recommend:
- 🌐 Hosting: Bluehost — what this blog runs on
- 🛒 Tech Gear: My Amazon Store — keyboards, monitors, dev tools I use
Purchases through my links help keep this blog ad-free 💙
Enjoyed this post?
Subscribe to the newsletter or follow on YouTube for more dev content.
🎬 Watch Shorts